10.2. Subscriber¶
A user with the permission “Editing and deleting pipelines” can open the Remote Data Subscription configuration page via the main menu entry Remote Data Subscription. The tab “Remote data subscriptions” is where you set up your subscriptions.
10.2.1. Retrieving published data¶
Permissions for Remote Data Subscription¶
The first step in configuring Remote Data Subscription is to obtain the correct credentials for an account on the Publisher DISQOVER installation. The account must have the permission “Subscribing to published RDS data”.
Configuring the Subscriber¶
Subscribing to a publisher¶
To add a new Remote Data Subscription you click the “+ Subscribe to publisher” button. In the popup screen you enter a name for the publisher you want to connect to and the connection details.
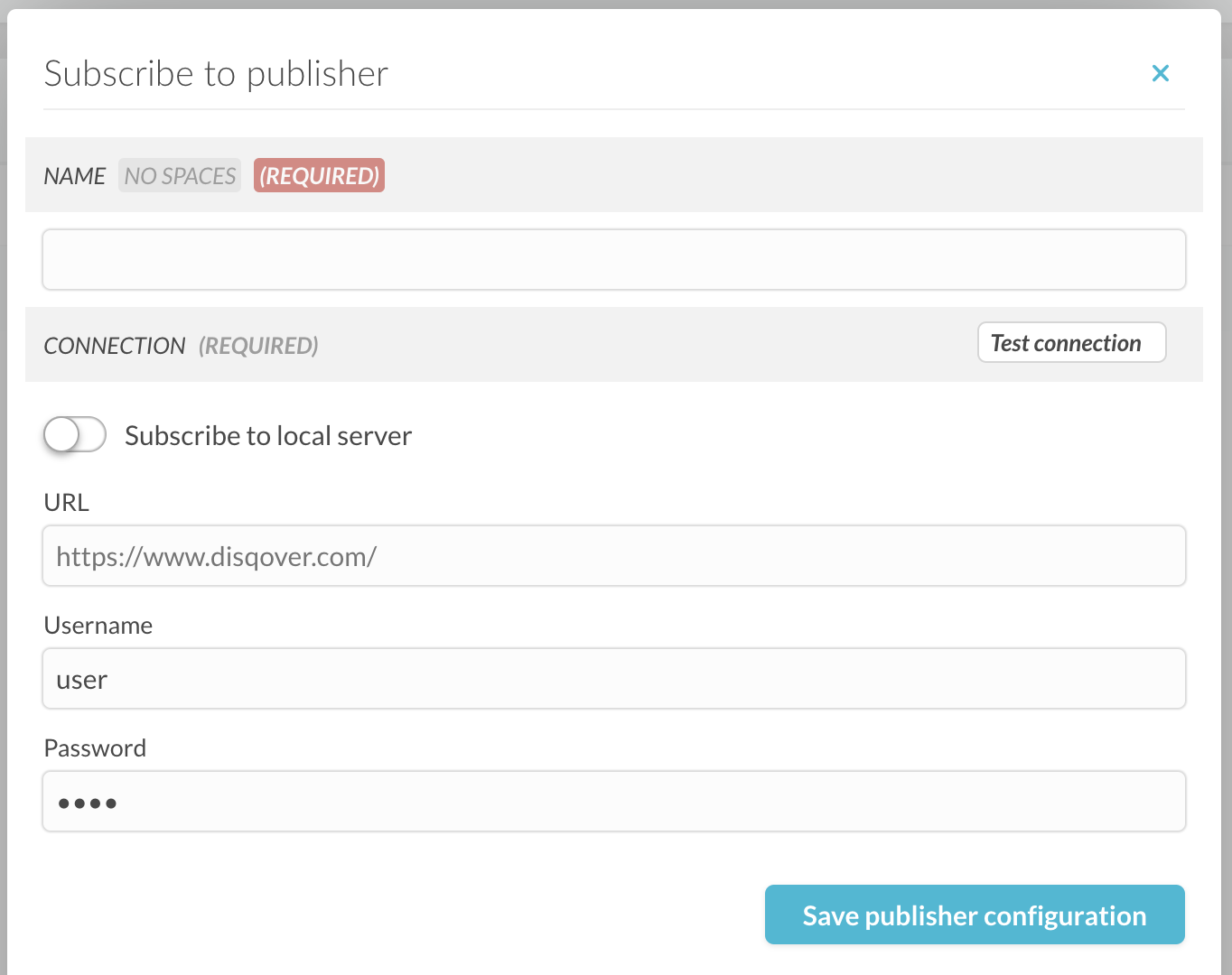
Figure 10.2 The Subscribe to publisher popup screen.
The username and password are the ones for the account obtained from the remote server.
Note that if your installation also acts as a Remote Data Subscription Publisher and you wish to subscribe to it you can do this by checking the “Subscribe to local server” toggle.
Creating subscriptions¶
Now that you have subscribed to a publisher, you can create subscriptions where you can select which data sets you want to retrieve. Click on the “Add subscription” button to create a first subscription. You will see an input field where you can enter a name for this subscription and a list of available data sets on the remote publisher, where you can select which datasets you want to retrieve. When done, click the save button.
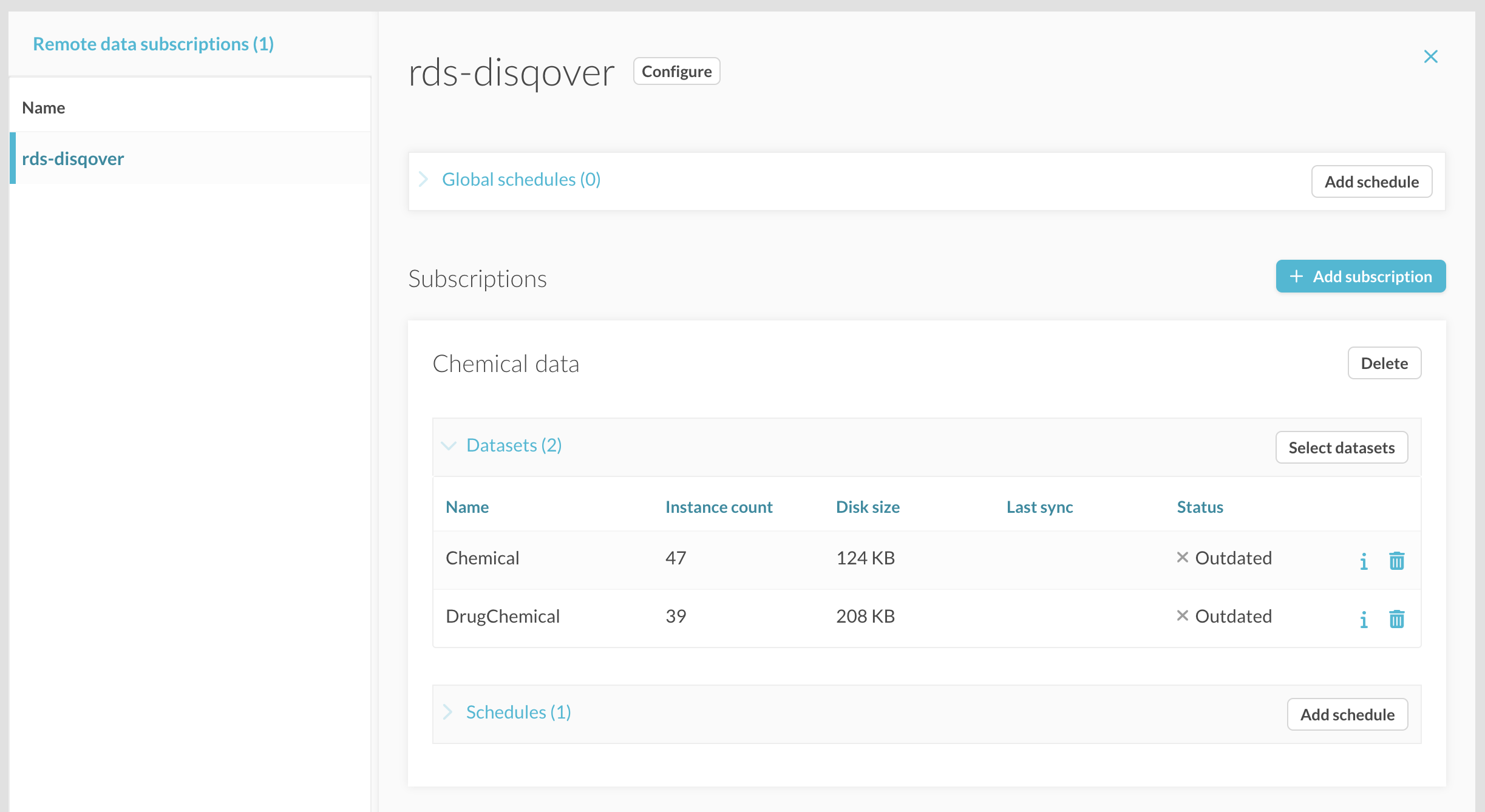
Figure 10.3 Creating a subscription
Retrieval schedules¶
For each subscription you created you can configure one or more scheduled retrievals. Click on the ‘Add schedule’ button in the created subscription section to create a new schedule.
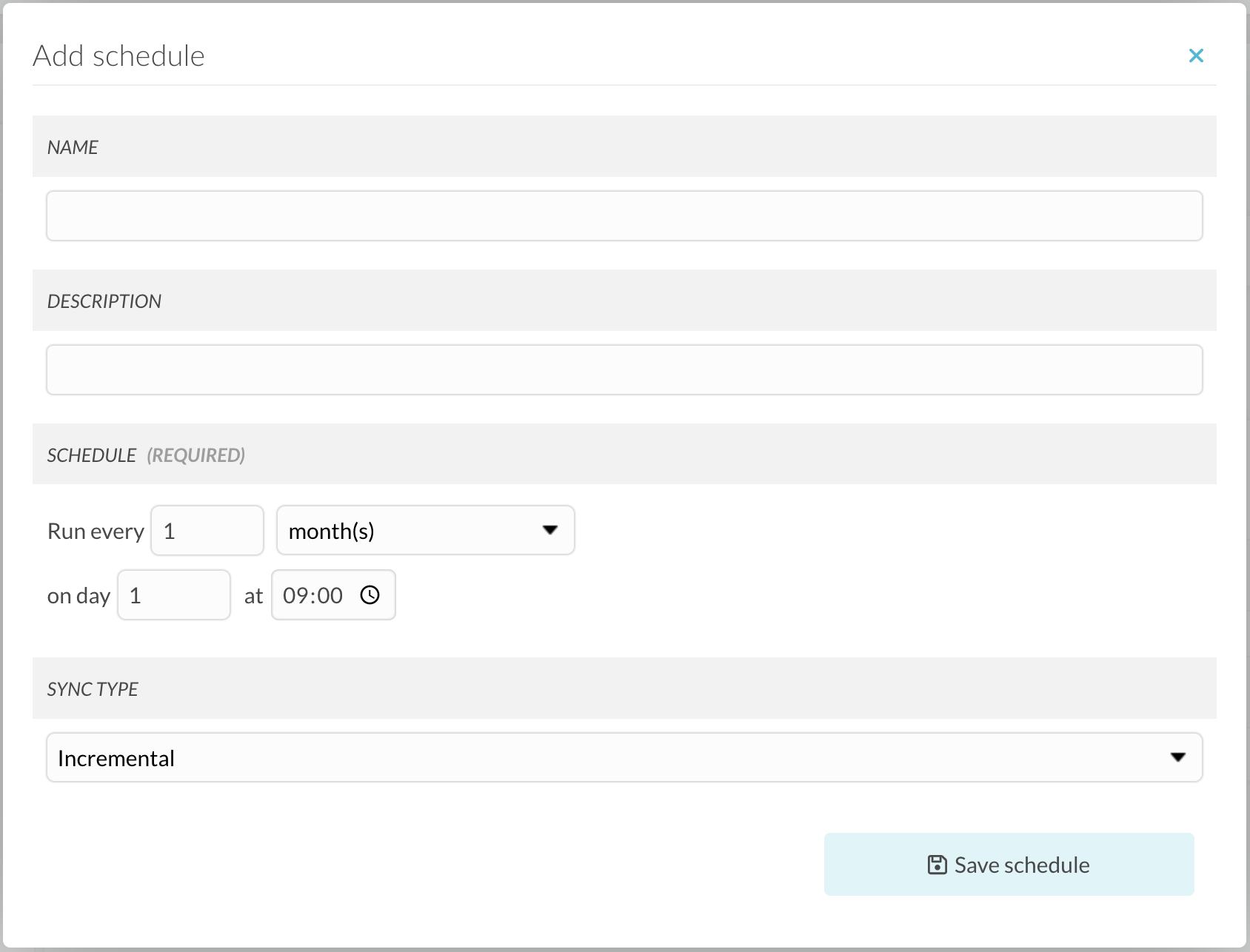
Figure 10.4 The Configure schedules popup screen.
You can also create a schedule for the whole publisher, by clicking on ‘Add schedule’ button in the ‘global schedules’ section. This schedule will synchronize all subscriptions for the publisher at once.
A note on schedule types¶
The Remote Data Subscription schedule provides two types of data retrieval:
- “FULL”: A full schedule will remove all existing data in the local Data Sets and download all files for this Data Set again during the next scheduled execution.
- “INCREMENTAL”: An incremental schedule will only add new files and delete removed files in the Data Sets. This is quicker than a “FULL” schedule.
The recommended setup is a mix of both schedule types. For example: a daily incremental schedule and a weekly full schedule, or a weekly incremental and a monthly full. This ensures minimal data processing on a regular (daily) basis, but ensures full data integrity by sometimes downloading the entire Data Set.
At the end of a successful data retrieval, the size and count statistics are updated and the Data Set is available for use in a pipeline.
10.2.2. Ingesting published data¶
Importing a Remote Data Set¶
Once you have retrieved one or more Remote Data Sets as described above, you can import the data in a pipeline as you would import regular files (CSV, XML, …). Because Remote Data Sets are stored and transmitted in the internal data format of the Data Ingestion Engine, importing is very fast.
For each Remote Data Set you want to import, you have to create an Import Remote Data Set component in the pipeline, and fill in the correct options.
All instances of a Remote Data Set will be imported in a new class.
The option Predicates allows you to select which predicates you want to import, and also provides
the possibility to rename the predicates. For example, you can import predicate surname.lit but rename it to name.lit.
A scanner is available to fill in this option, based on the predicates present in the Remote Data Set.
Note that URIs, Preferred URI, labels and Preferred Label will always be imported automatically. You cannot specify these in the option Predicates.
It is also possible to leave the option Predicates empty. In this case all the predicates of the Remote Data Set will be imported. Since version 6.01 this behavior is deprecated.
It is possible to specify a Predicate Prefix which will be prepended to each predicate name.
This can be used e.g. to avoid clashes with existing predicate names.
For example, if you give Predicate Prefix the value “remote”,
then RDS predicate parent.fwd will be imported as remote:parent.fwd.
Note that the predicate prefix will not be applied to imported predicates which are explicitly renamed
or to predicates which already have a prefix.
Remote Data Sets may also include relationship predicates (.fwd) linking to instances of the same Remote Data Set or linking to instances of another Remote Data Set. In the latter case, if you want the links to resolve, you have to retrieve and import those other Remote Data Sets as well.
Execution¶
In order to minimize processing time, Import Remote Data Set components will try to run incrementally if possible. If the latest data retrieval included some changes to the Remote Data Set, for example if some instances have been added, some removed and some updated, only those instances will be processed. Of course the first time the component is executed all instances will be processed.
If there is any change in the predicates in the Remote Data Set, e.g. if it contains a new predicate, then execution will be non-incremental. It is also possible to force a non-incremental execution by clearing the RDS, see Advanced Topics.
If a Publisher publishes an update of a Remote Data Set (containing, for example, more recent data), then the user can choose to obtain that update by executing a schedule (see above). In that case the Import Remote Data Set component will become out-of-date and will be re-executed when the pipeline is executed. So please note that this is a two-step process: 1. retrieve data, 2. run the pipeline.
Creating a Canonical Type from a Remote Data Set¶
A Remote Data Set does not only contain regular data (instances and their predicate values), but also configuration data that was specified when creating the Remote Data Set. This information contains URI, label, description and more of the Canonical Type and its properties. It also contains information about Typed Links between Remote Data Sets on the same Publisher.
That information can be used to automatically populate the options of a Configure Canonical Type component
or a Configure Typed Link. Use the ‘scanner’ button ( ) in the top right corner and fill in the appropriate options to do so.
) in the top right corner and fill in the appropriate options to do so.
Note that the scanner will overwrite existing option values in the component. Also, it may be necessary to make some manual corrections in the proposed option values. If an update of a Remote Data Set changes the configuration, then it may be necessary to re-scan.