10.1. Introduction¶
Remote Data Subscription (RDS) is a novel way to integrate data that has been prepared by other DISQOVER installations.
Figure 10.1 shows a schematic overview of the interaction of two DISQOVER installations with Remote Data Subscription.
For a step-by-step walkthrough of setting up Remote Data Subscription, see section 9.3.9.
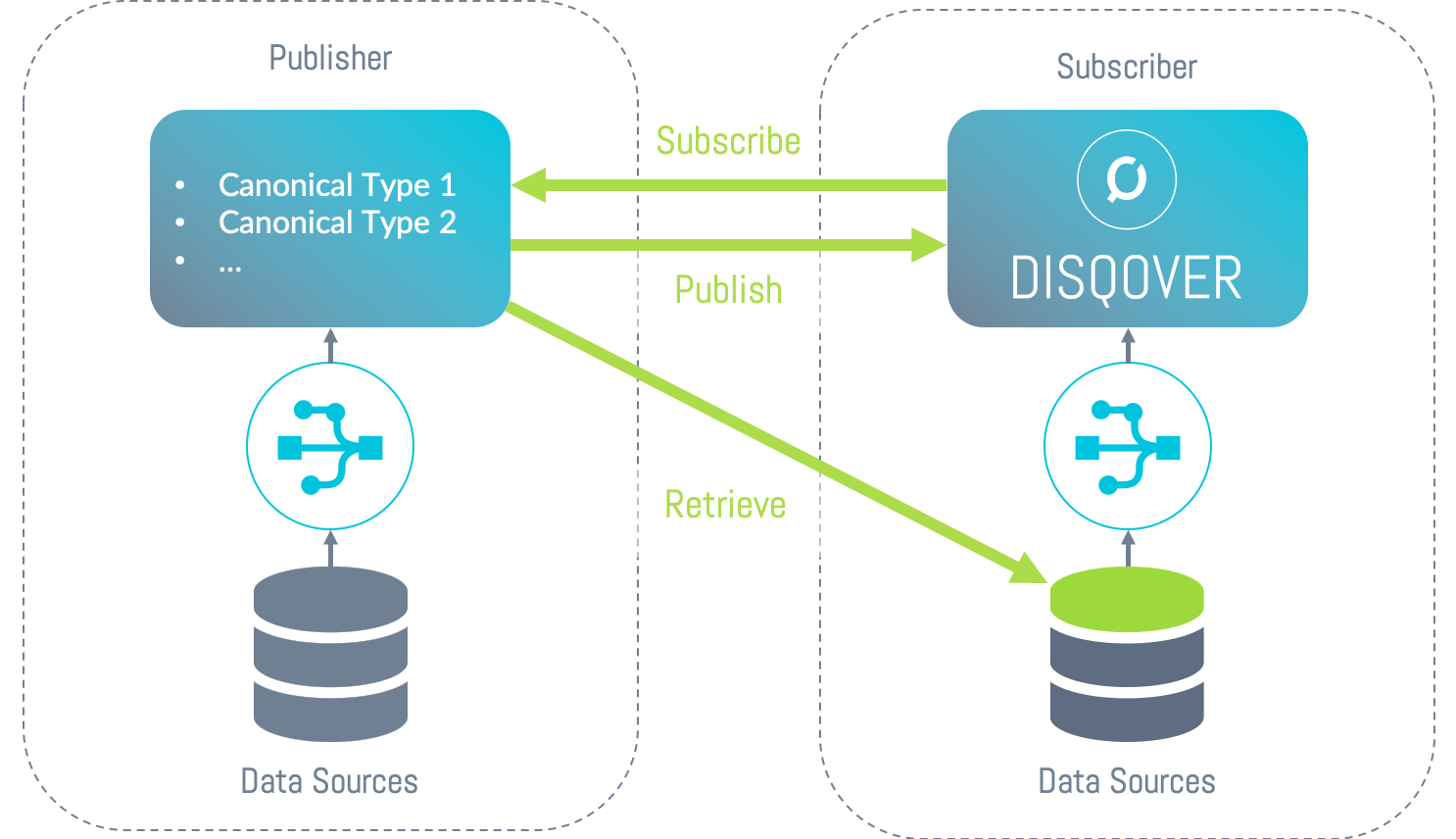
Figure 10.1 Schematic overview of Remote Data Subscription.
10.1.1. Concepts¶
A Remote Data Set is essentially a set of instances with a fixed set of predicates, similar to a class in the Data Ingestion Engine, which can be transferred from one Data Ingestion Engine pipeline to another.
On the publishing side the publishing pipeline can publish one or more Remote Data Sets, i.e. makes them available for retrieval.
On the subscribing side a user can
- subscribe to one or more Remote Data Sets published by an RDS publisher,
- retrieve the data, and
- import the data in an “importing pipeline”.
Remote Data Sets are stored and transmitted in the internal format used by the Data Ingestion Engine which results in very fast downloads and imports.
For more details, please refer to section 10.2 for the subscriber side and section 10.3 for the publisher side.
Note that publisher and subscriber can be different DISQOVER installations, even on different servers, or the same DISQOVER installation.
ONTOFORCE publishes some highly curated Remote Data Sets that are ready to be retrieved and imported. But any organization can publish their own Remote Data Sets and make them available for internal or for public use. For example, you can use separate pipelines to import (regular) data and do some initial clean-up, then integrate the results in a different pipeline.
10.1.2. Components¶
Components Architecture¶
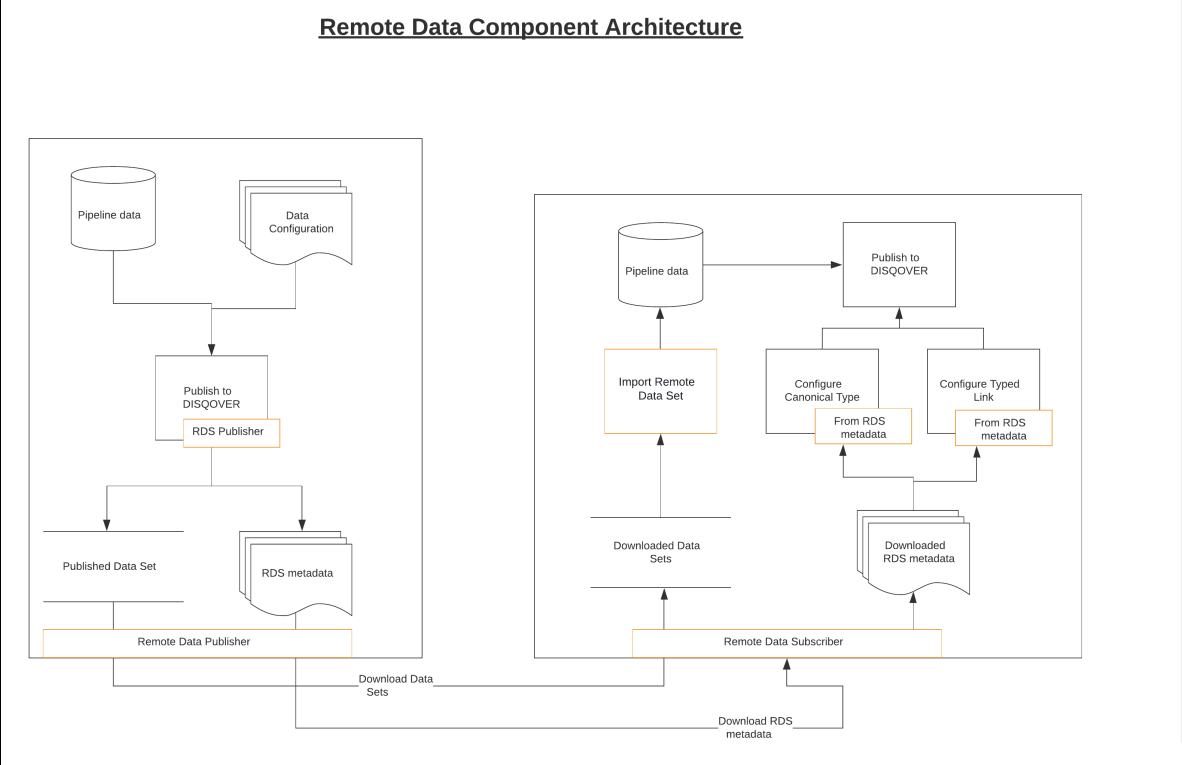
Remote Data Publisher¶
The Remote Data Publisher is part of the pipeline indexing component and only active when Publish to RDS is set at the start of the pipeline run. This component is responsible for processing all instances and writing them to the appropriate Remote Data Set. It also generates a configuration for Canonical Types and various internal metadata files (file list, columns, statistics, ..).
It works independently of other publishers (like ‘Publish to DISQOVER’ or ‘Export to TTL’) and only processes Canonical Types that were selected to be published as Data Sets.
In each deployment, if a Remote Data Publisher is active, A Remote Data Subscriber can:
- get Publisher information (e.g.: software version)
- list the available Data Sets
- retrieve information about a Data Set
- retrieve a file list for a Data Set
- retrieve a file from a Data Set
All endpoints are reachable from https://<public hostname of the Publisher>/api/rds
Remote Data Subscriber¶
The Remote Data Subscriber is responsible for (periodically) downloading Data Sets from Remote Data Publishers. It has two internal subcomponents:
- A scheduler: responsible for executing jobs to download a Data Set when the scheduled time is reached.
This process runs independently in the background. Running schedules in parallel is currently not supported.
- A configuration service: a service for the DISQOVER UI to configure Remote Data Publishers, select Data Sets and create schedules.
Remote Data Importer¶
The Remote Data Importer is a Data Ingestion Engine pipeline component, available as “Import Remote Data Set”. It allows the user to import data from Data Sets downloaded by the Remote Data Subscriber into a Data Ingestion Engine class. It does not download data itself, nor does it contact the Remote Data Publisher.
Remote Data Configuration Scanner¶
An imported Remote Data Set also contains configuration information which can be used to configure a Canonical Type based on that Data Set or to configure Typed Links betweens Data Sets. To that end the Configure Canonical Type and Configure Typed Link components offer a scanner which can fill in the component options, similar to the scanners in normal import components.